

/image%2F1934921%2F20171024%2Fob_d9d788_blog.jpg)
Déploiément du Node Client (EdgeNode) sur le cluster Hadoop
Une fois que notre cluster Hadoop multi-nœuds est en cours d'exécution, nous allons créer un EdgeNode ou un GatewayNode. Les nœuds de passerelle servent d 'interface entre le cluster Hadoop et le réseau extérieur. Le EdgeNode est utilisé pour exécuter des applications clientes et des outils d'administration de cluster.
Le EdgeNode ne doit pas faire partie du cluster, il faudra des composants de base tels que les binaires Hadoop et le courant Fichiers de configuration de cluster Hadoop pour envoyer des travaux sur le cluster. Nous installerons des outils clients dans notre EdgeNode, nommément HIVE, SQOOP, FLUME, PIG, OOZIE, etc. Avant cela, installons EdgeNode.
Configurez un noeud de bord pour que les clients puissent accéder au cluster Hadoop pour soumettre des travaux.Donc, actuellement, notre cluster hadoop se présente comme suit:
Hadoop namenode: 192.168.3.207 ( NameNode )
Hadoop datanode : 192.168.3. 34 ( DataNode1 )
Hadoop datanode : 192.168.3.51 ( DataNode2 )
Hadoop edgenode : 192.168.3.52 ( EdgeNode )
Étape 1. Installez Java sur le NameNode
L’installation du edgenode nécessite Java comme pré requis. Nous utiliserons jdk 8.
* telechager sur le site oracle jdk 8
* transferer à l’aide de winscp dans le repertoire /usr/lib/jvm
* executer la commande en tant que root: rpm -Uvh jdk-8u131-linux-x64.rpm
Étape 2.Configurer l'alias de la machine 192.168.3.52 dans le fichier hôte
Ensuite, nous devons modifier le fichier hôte pour mettre l'alias du nom de l'ordinateur. Il faut juste editer le fichier hosts avec editeur VI à travers la commande:
* vi /etc/hosts
Une fois le fichier ouvert, ajouter :
192.168.3.52 EdgeNode
192.168.3.207 NameNode
192.168.3.34 DataNode1
192.168.3.51 DataNode2
à la fin du fichier, enregistrer et fermer.
Étape 3.Configurer le serveur SSH
EdgeNode requiert moins l'accès par mot de passe au NameNode. SSH doit être configuré, pour autoriser le login sans mot de passe de EdgeNode au NameNode dans le cluster. La façon la plus simple d'y parvenir est de générer une paire de clés public / privé, et la clé publique sera partagée avec le noeud principal.
Nous allons Générer une clé SSH pour l'utilisateur root avec cette commande:
ssh-keygen -t rsa -P “ “
Nous executerons ensuite la commande suivante qui nous permettra de faire entrer le fichier dans lequel enregistrer la clé en octroyant des droits :
cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
Et ensuite Copiez maintenant la clé publique du EdgeNode et collez dans le fichier /root/.ssh/authorized_keys dans NameNode.
Étape 4.Obtention des fichiers de distribution et de configuration Hadoop:
nous allons copier tous les binaires hadoop et les fichiers de configuration présents dans le NameNode dans notre EdgeNode, de sorte que nous ayons la même version des binaires Hadoop que dans le cluster et les détails de configuration de notre cluster. En tapant la commande:
Scp -r root@NameNode:/usr/local/hadoop /usr/local/
Étape 4.configuration Variables d'environnement :
Maintenant, nous allons ouvrir le fichier .bashrc avec la commande: vi ~/.bashrc et copier les lignes ci-dessous à la fin de votre fichier :
export JAVA_HOME= /usr/java/jdk1.8.0_131/jre
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export CLASSPATH=$CLASSPATH:/usr/local/hadoop/lib/*:.
Étape 5.Confirmer que Hadoop Cluster est accessible depuis EdgeNode:
Nous allons tester le système de fichiers hadoop depuis notre edgenode avec la commande:
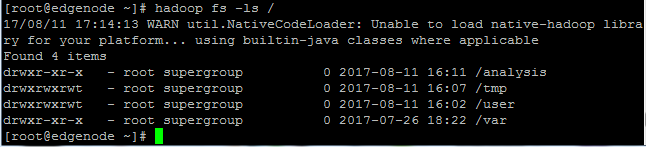
hadoop fs -ls /
Sur cette capture nous pouvons voir les fichiers present sur notre NameNode à partir de notre Edgenode.
Étape 6.Il est temps de tester le job mapreduce.
Ce job MapReduce permet d'estimer la valeur du nombre pi avec 2 comme valeur de Map et 4 comme valeur de Reduce. Avec la commande:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar pi 2 4
il ne requiert pas de fichiers depuis le système de fichiers HDFS.
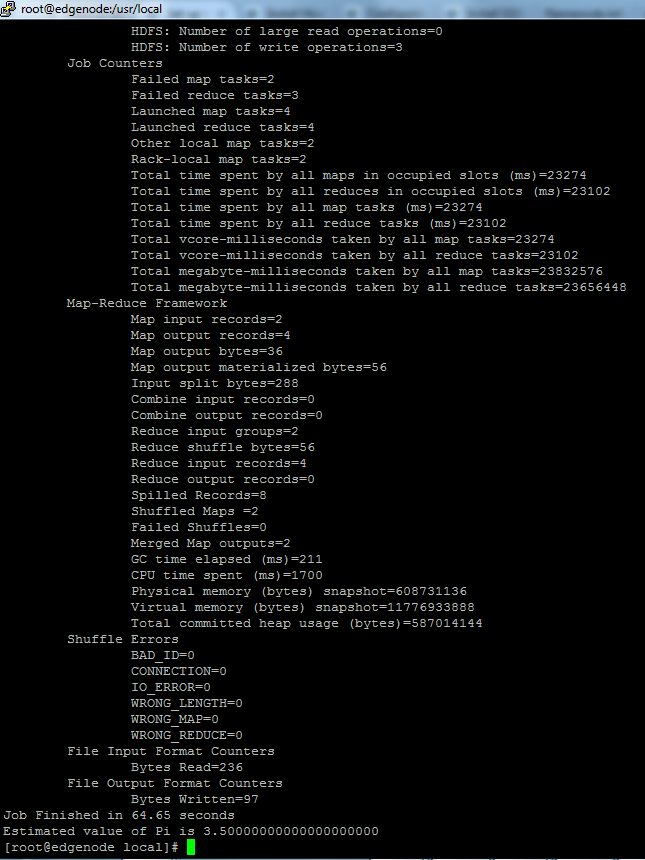
Et ça wakaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!!!!!!!!!!!!!! dans notre prochain article nous deploierons le client HIVE sur notre Edgenode.



/image%2F1934921%2F20191217%2Fob_4fdf81_blogpic1.png)
/image%2F1934921%2F20190123%2Fob_aa4566_oozie.jpg)
/image%2F1934921%2F20190120%2Fob_9d83e4_hve.png)
/image%2F1934921%2F20190109%2Fob_99d655_sqoop-blog.png)
/image%2F1934921%2F20170717%2Fob_b1c54c_big-data.jpg)